Write
The most common task when working with an archiving environment is writing archive files. This section contains explanations and instructions that guide you through the most important actions to be performed when using standard archiving and version archiving.
Archived contents
The archived SARA - Database Tables (H) contain all specification objects.
Extension
The list of structures can be easily extended per archiving object via transaction AOBJ by extending the structure definition there. Only flat structures can be entered here, either of type Transparent table or Simple structure. Attention: When adapting the structure definition, all relevant archiving objects (/SCT/QP and /SCT/QPV) must be adapted equally.
Furthermore, to fill the data accordingly, the following methods must also be adapted:
/SCT/QP_CL_ARC_ADK->PUT_NODE_DATA
/SCT/QP_CL_ARC_ADK->GET_NODE_DATA
Standard archiving
Standard archiving is the standard method for archiving productive master data. The specifications to be archived must be marked for deletion so that they are recognized by the write task. After starting an archiving run, all marked specifications are collected in the first step. In the next step, a new archive file is created in which an exact copy of the productive data is stored. After successful writing, the delete task is executed for the archived specifications to physically remove them from the productive database.
Execute (F8) Standard archiving
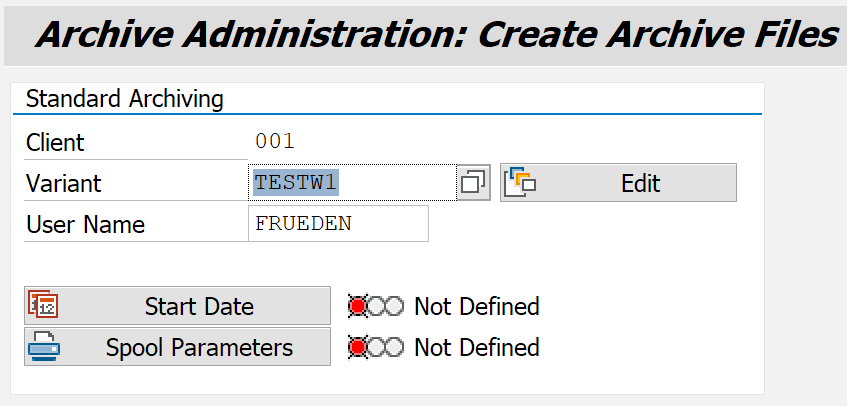
The execution of a write task with the transaction SARA is done as follows
Click on Write
Select or maintain a variant analogous to preprocessing (deletion flag)
Click on the Start date to configure it.
Click on Execute in the application toolbar
After clicking the Execute function (F8), a new job is scheduled to be executed immediately or in the future, depending on the configuration of the start date. After the job has been completed, the results can be viewed in the logs and/or in the job overview....
The screen for variant maintenance differs slightly from the variant maintenance for the "preprocessing".
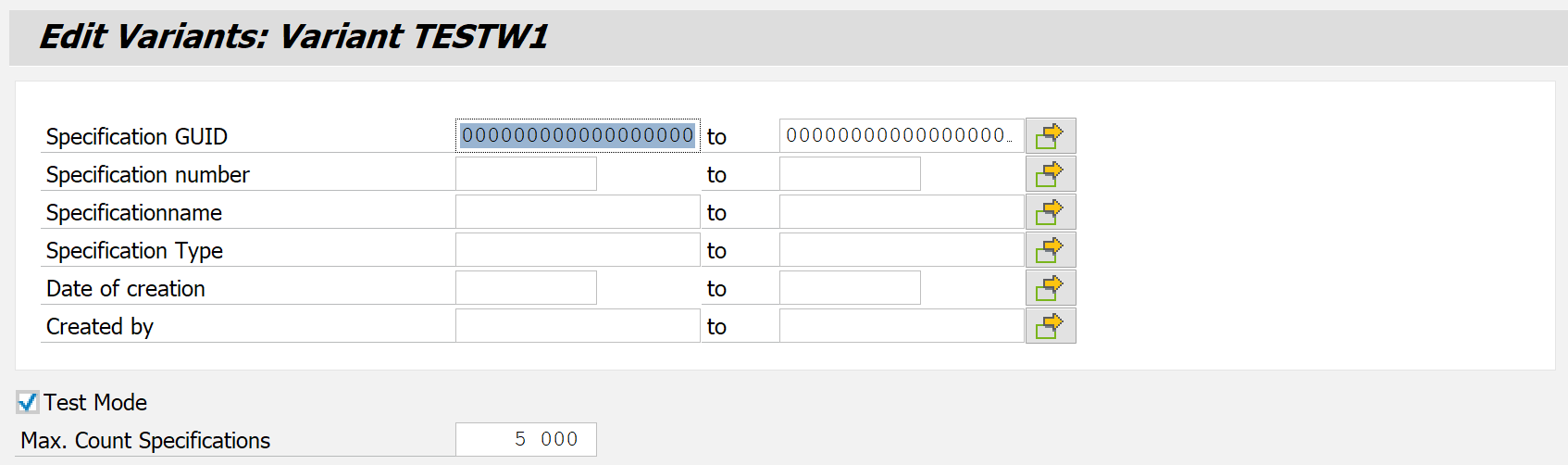
The first options in this screen allow you to restrict the specifications for archiving using ranges for some of the most important attributes. It should be noted that the actual selection is always reduced only to the data marked for deletion so that only the corresponding specifications form the range accessed with this additional filter. The data selected here is always only a subset of the data determined in "Preprocessing".
When the test mode is activated, all actions are performed as usual, but no archive file is created. The logs and statistics are still written, so this feature is very useful if you want to preview how a task was performed.
The last option available at this point is again the Maximum Count of specifications. It can be helpful to perform the write operation in several steps to avoid possible memory and performance losses.
Automatic deletion
If the archiving object is adapted accordingly, the ADK framework triggers an automatic delete task for all successfully archived specifications after the write task is completed.
Version archiving - /SCT/QP_AVER
Sometimes it can be helpful to keep a single or even multiple versions of one or more specifications, whether for backup, migration, or other reasons. Version archiving therefore provides a simple and highly reliable way to store snapshots of specifications in migratable archive files and restore them as needed. Written files and specifications contained therein are tracked in conjunction with freely definable archive IDs, called ARCID for short, and in the following.
In contrast to standard archiving, version archiving is simpler and more suitable for specific transactions instead of SARA.
Archive generation (ARCID)
There are two ways to create a new ARCID as an identifier for your version archiving run. After you have either opened transaction /SCT/QP_AVER or entered an appropriate layout maintenance, follow one of the instructions below.
The first way is suitable if you want to define a specific ARCID and a corresponding description to perform the write task manually.
Click on Create Archive
Enter a user-defined archive ID.
Select an archiving type
(Optional) Enter the description of the desired content
Click on Create archive
The second way is suitable if there is no motivation for further specifications or if you want to use version archiving as a backup functionality, i.e. you plan an automatic execution in certain intervals.
When starting the execution, the Archive ID field is left empty and an ARCID is created automatically. The ID consists of an underscore as a prefix, followed by a number corresponding to the next incremental version, taking into account the previously created automatic ARCIDs. For example, if there are already three automatic ARCIDs in the system (1-3), the following would be newly created: "_4". To be able to distinguish these not-very-meaningful identifiers, the description is set to the date and time of the start of the archiving run.
Execute version archiving
Open transaction /SCT/QP_AVER and the initial screen of version archiving appears.
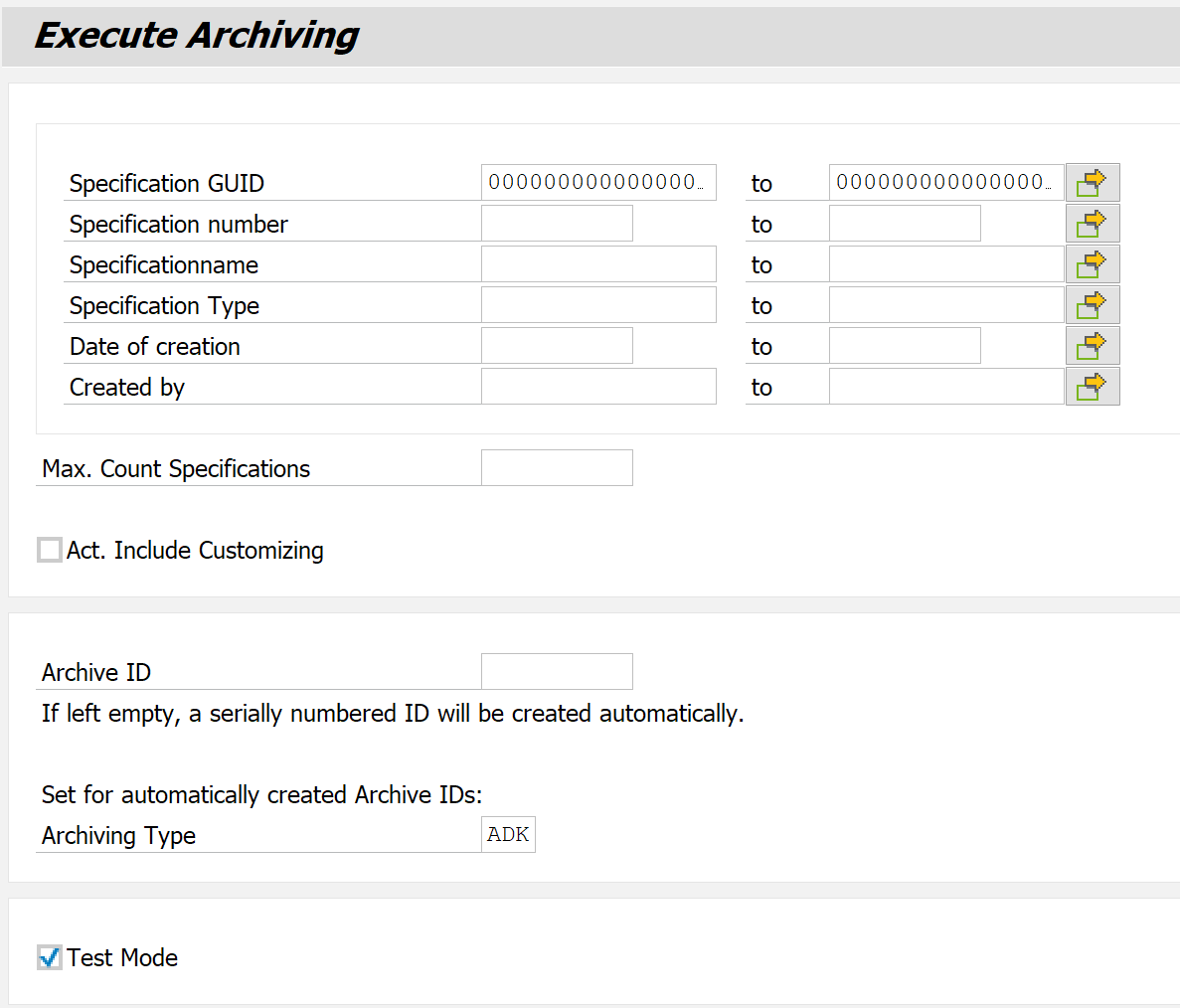
With the first option, the parameters for archiving can be restricted as before by specifying ranges for some of the most important attributes. The input here is obligatory since in the normal case the entire database is not to be archived.
The Maximum number of specifications is intended for the case when large amounts of data are to be archived. In such a scenario, it can be helpful to be able to perform the task in several steps to avoid possible memory and performance losses.
As described above, the Archive ID can be entered to archive to a specific ARCID, which must have been previously created using the Create Archive function in the application toolbar. Otherwise, this field can be left blank, which will result in an ARCID being created automatically.
With test mode enabled, all actions are performed as usual, but no archive file is created. The logs and statistics are still written, so this feature is very useful if you want to check the execution of a task before actually running it.